5 Layers of the Monitoring Stack

In a perfect post-#monitoringsucks world, operations teams would have a single, magical tool that would provide capacity planning, self healing, trending information, system alerts, and application monitoring across your entire infrastructure. In reality, Infrastructure Operations has to make a choice between forcing a single monitoring system into multiple roles or choosing a best of breed solution for each component of the system. At Ping, we've chosen the latter.
We've done a few things to reduce some of the complexity associated with running multiple monitoring platforms.
The first, and most obvious, is to utilize cloud-based monitoring systems whenever possible. Cloud based applications iterate quickly and are generally very easy to implement with common automation tools like Puppet or Chef. SaaS monitoring applications also do not require server resources, database & version upgrades, or a dedicated administrator. Teams can be brought up to speed quickly and easily trained. With the exception of Splunk, we've managed to migrate almost all of our monitoring systems to the cloud.
The second thing we did was to identify and organize what components of the system we wanted to monitor (duh). Breaking these down among all production and supporting systems and coming from network engineering, we came up with the 5 layers of our monitoring stack. The layers are organized much like the 7 layers of the OSI stack. It starts at the networking level, and progresses up through the system to the external public facing endpoints. As you move up the stack, each layer becomes more and move immediately visable to the customer.
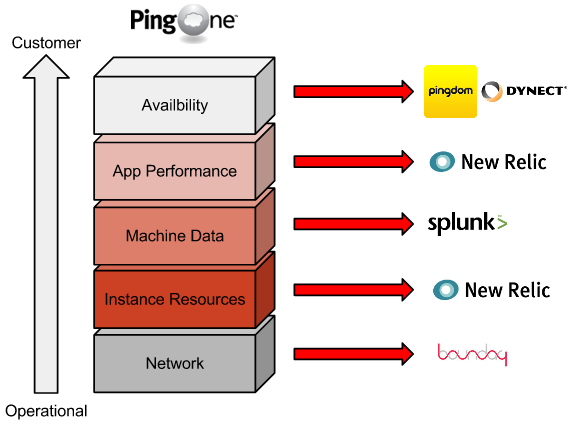
Availability Monitoring
External availability monitoring is used to view all applications and services from agents outside the production network, and report on customer facing outages when network connectivity, services, or software bugs bring down an entire service endpoint. This type of monitoring should use application heartbeats and not simple ICMP or port connectivity. Reporting should include calculated SLA uptime, and alert on-call engineers whenever issues are reported. We use a combination of DynDNS and Pingdom to function as our external availability monitors, and have designed specific applications heartbeats for each of these services. Pingdom also provides public uptime statistics for us and functions as an unbiast 3rd party for SLA compliance.
Application Performance Monitoring
APM gives a detailed view into how the applications themselves are behaving as they run on top of the rest of the stack. This layer can be extraordinarily advanced in the detail of instrumentation. Offerings like New Relic, AppDynamics and Keynote have become very advanced in recent years. Not only can this type of monitoring provide excellent visual displays of your application, but they also give development teams direct views into how to diagnose and fix issues within their code. Agents collecting metrics also have the ability to insert timers and gather information on end-user load times at the browser. This aspect of APM is caled "Real User Monitoring," or RUM, which illuminates actual customer experience across the system. Ping Identity chose New Relic for this particular layer of the stack for it's quick deployment cycle, cost effectiveness and ability to span more than one layer of our Monitoring Stack.
Machine Data Collection
Collection and analysis of machine data is a key metric for monitoring the health and activity of each instance or device within the system. Logs and other raw formatted data can be organized into events and classified by severity into what is commonly known as "Operational Intelligence" or OI. Events and usage metrics can be displayed in custom dashboards to create a useful visual representation of thousands of data points. Machine data can be leveraged on the business side of the organization as well, building detailed usage information for billing and other purposes. Like a lot of enterprises, Ping uses Splunk for this layer of our stack. However there are many new players in this area, including the open source Logstash and the cloud-based Loggly. We've found the machine data layer to be the most versatile layer in the monitoring stack.
Resource Monitoring
Resource monitoring instruments each instance to collect near real time and historical CPU, memory, and disk resources. These metrics are collected to correlate instance activity to other events within the system, and to alert if any instance becomes overloaded or unresponsive due to resource exhaustion. Resource metrics are also used to plan scaling activities within clusters of machines to attain the correct "steps" of scale and retain maximum efficiency of the system. Historical trending is also used to accurately deploy new resources before they're exhausted. We've found added value with New Relic here, as their offering covers this layer of our stack and is free of charge for as many instances as you'd like. Many people still use Nagios and new comers like Zabbix and Icinga.
Network Monitoring
Systems and instances communicate with each other in any modern distributed system. These interactions over the network need to be continuously analyzed and organized into conversational context using different metrics. Host, service port, latency, round trip time, retransmit rates, and packet loss all need to be taken into account to collect a clear picture of inter-system communication. All production systems must be instrumented to report each of these metrics in as near to real time as possible. We've found that Boundary integrates well with our automated deployment systems and the diversity of our cloud deployments, although many people still use Cisco's Netflow.
In combining these 5 layers of our monitoring stack gives the Site Reliability Team the ability to detect faults within PingOne, and drill into the true root cause of issues in very short periods of time. We can identify if datacenter links are in trouble, quickly diagnose application bottlenecks, peer into the end-user experience from a dashboard, and manage operational trends in the system with no suprises. It's worked very well for us so far, but we're always looking for ways to improve the stack and process with new metrics or methods to keep PingOne "Dial tone SSO."
About the Author: Beau Christensen is the Manager of SaaS Operations & Reliability at Ping Identity, responsible for cloud infrastructure architecture and reliability of all On Demand applications. bchristensen@pingidentity.com @beauchristensen
